Resiliência em Arquitetura: A Decisão é Estratégica, não apenas Técnica
O custo da alta disponibilidade: a resiliência se inicia em decisões estratégicas, não na tecnologia
Staff Engineer @Serverless Guru | AWS Community Builder | Specialist in Serverless, AWS & Event-Driven Architectures | Speaker & Content Creator @willpeixoto.dev
🇺🇸 Also available in English: Resilience in Architecture: The Decision Is Strategic, Not Just Technical
Depois de um outage grande como o que vimos recentemente na AWS, a fumaça sobe e, invariavelmente, surgem as mesmas perguntas que assombram CTOs e arquitetos:
Deveríamos estar em multi-região?” ou pior (e até um pouco nostálgica) — “Será que deveríamos voltar para o on-premise?”
A verdade é que a resposta certa raramente é técnica.
Ela é, antes de tudo, estratégica.
Como o próprio Werner Vogels (CTO da AWS) costuma cravar em suas palestras:
“Everything fails, all the time.” (Tudo falha, o tempo todo).
E é exatamente isso. A questão central não é se vai falhar, é quando vai falhar e como você estará preparado quando esse momento inevitável chegar. Porque ele virá. Quer você esteja na nuvem, no on-premises ou em uma complexa arquitetura multi-cloud.
O que realmente diferencia times resilientes não é a ausência de falhas, mas a velocidade, clareza e eficácia com que respondem e se recuperam.
E é aí que entra a verdadeira maturidade arquitetural: resiliência não é sobre escolher "multi-região" ou "on-premises" — é sobre entender o risco inerente, documentar a escolha de forma transparente e reagir com um plano.
1. O Contexto por Trás da Pergunta: O Paradoxo da Falha Visível
Toda vez que há um grande outage, noto que times técnicos e executivos tendem a se dividir entre duas reações extremas, movidas pelo medo e pela pressão:
“Precisamos ser multi-região urgente! O custo é secundário!”
“Tá vendo? Cloud não é confiável. Devíamos ter ficado on-premise, onde tínhamos o controle!”
Ambos os extremos são atalhos perigosos.
Multi-região não é uma vacina contra a indisponibilidade, e voltar para o on-premise não é sinônimo de controle (apenas transfere a complexidade de manutenção).
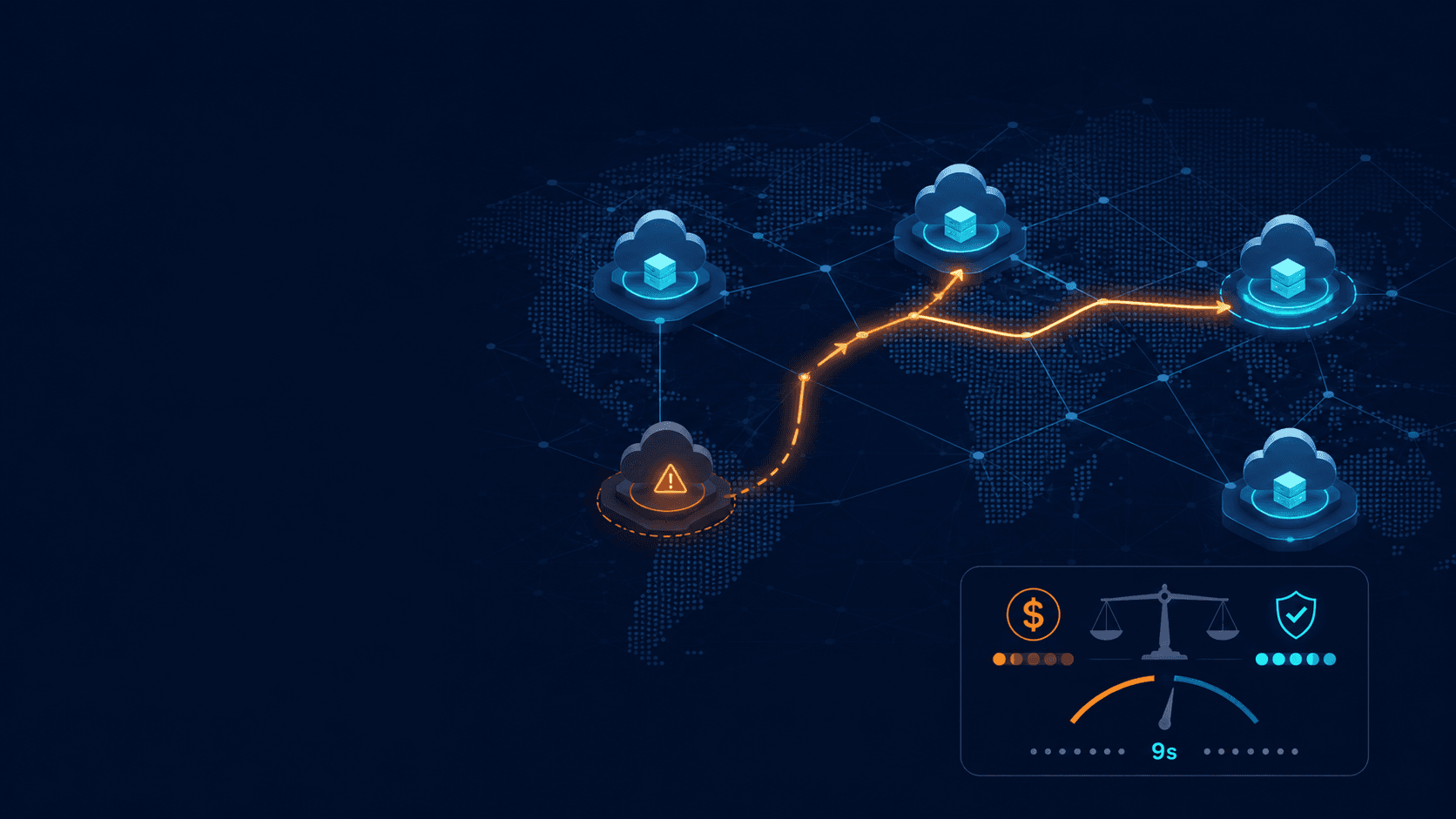
Ponto de Reflexão Crucial: A nuvem não falha mais do que um data center tradicional — ela apenas falha de forma mais visível, compartilhada e, ironicamente, democrática. Na AWS, os problemas escalam globalmente e se tornam trending topics em minutos. No on-premise, eles ficam escondidos atrás de logs dispersos, longos tempos de reparo e, muitas vezes, apenas impactam você. Honestamente, você acredita que sua empresa tem uma capacidade superior à AWS (ou a qualquer grande cloud provider) para gerenciar a segurança física, o cabeamento, a energia, o resfriamento e, principalmente, a resiliência de uma infraestrutura em escala global?
Migrar ou evoluir a arquitetura, no fundo, não é sobre “jogar tudo fora” ou “comprar o hype”. É sobre aproveitar o que o legado tem de bom e eliminar o que limita o crescimento.
Não é uma briga maniqueísta de “Cloud vs. Data Center”. É um jogo estratégico de Resiliência Consciente vs. Zona de Conforto.
2. Custo vs Continuidade: A Economia por Trás dos 9s
No mundo da infraestrutura, cada "9" adicional no SLA (Service Level Agreement) não apenas custa, mas custa exponencialmente mais.
Para ilustrar o impacto real de cada nível de disponibilidade, veja o downtime máximo permitido por ano:
99% (Dois 9s): Cerca de 3,6 dias fora do ar por ano. Custo e complexidade: Base (Custo 1x).
99,9% (Três 9s): Cerca de 8 horas e 46 minutos fora do ar por ano. Custo e complexidade: Custo 1,5x a 2x o ambiente base.
99,99% (Quatro 9s): Cerca de 52 minutos fora do ar por ano. Custo e complexidade: Custo 2x a 3x. Exige Multi-AZ e automação forte.
99,999% (Cinco 9s): Cerca de 5 minutos fora do ar por ano. Custo e complexidade: Custo 3x+. Exige automação impecável e, muitas vezes, arquitetura Multi-Region.
Cada salto de nível exige não só duplicar ou triplicar a infraestrutura, mas também exige revisão e sofisticação operacional. E o pulo do gato é que cada 9 adicional precisa ser justificado em ROI (Retorno Sobre o Investimento), e nunca em orgulho técnico.
📢 O Fator Inegociável: Regulamentação Para setores como financeiro, saúde (LGPD) ou telecomunicações, a escolha do SLA nem sempre é puramente econômica. Muitas vezes, o requisito de disponibilidade (e a capacidade de recuperação de dados, o RPO) é imposto por lei ou normas setoriais. Nesses casos, o debate não é se podemos pagar, mas sim como atingir o SLA legalmente obrigatório com o menor custo e complexidade possíveis, pois o custo da multa regulatória supera qualquer economia técnica.
Regra Prática de Complexidade:
Alta disponibilidade (dentro de uma única região): Pode custar 1,5x a 2x o ambiente base.
Multi-Região (Active/Passive): Pode custar 2,5x a 3x.
Multi-Cloud (Active/Active): Quase nunca reduz risco. Pelo contrário, normalmente aumenta a superfície de falha e a complexidade operacional.
3. Decisões Conscientes: A Virtude dos ADRs
Toda escolha arquitetural é um compromisso baseado em um contexto — e esse contexto é volátil. Sem registro, o contexto se perde, o que nos condena a refazer decisões, revisitar discussões e incorrer em custos desnecessários.
É aí que a prática dos ADRs (Architecture Decision Records) se torna crucial. Não são documentos longos de 50 páginas, mas sim documentos curtos que capturam a decisão, o motivo e o risco assumido em um dado momento.
Exemplo de ADR (com foco no risco assumido):
# ADR-014: Não usar replicação multi-região no MVP
Contexto:
- Tráfego atual < 10 req/s.
- O custo de replicação multi-região é estimado em > 3x o custo atual.
Decisão:
Manter arquitetura single-region (usando Multi-AZ para HA intra-região),
com backup cross-region diário.
Gatilho de Revisão:
Após atingir 100 req/s médios ou quando o SLA atual (99,95%) gerar
impacto de negócio.
Risco/Consequência Aceita:
Risco de downtime total do serviço em caso de um outage que afete a
região inteira (RTO estimado em 4 horas para recuperação cross-region).
Um ADR não evita a falha. Mas evita que a falha pegue o time de surpresa, pois o risco foi mapeado, assumido e justificado pelo negócio. É o mapa para as futuras discussões.
4. Resiliência Seletiva: Nem Tudo Precisa de HA (e tudo bem)
A resiliência seletiva é uma virtude de economia e clareza. Não é todo serviço que precisa de redundância global. Alocar recursos finitos (dinheiro e atenção de engenharia) em redundância desnecessária é um dos grandes desperdícios em arquitetura.
Priorize Alta Disponibilidade (HA) apenas para o que realmente importa:
Funções de Receita Direta: Componentes cruciais para a transação financeira (ex: checkout e APIs de pagamento).
Jornada Crítica do Cliente: Funções que impedem o uso do valor central do produto (ex: login ou catálogo principal).
Risco Regulatório e Legal: Serviços onde a falha gera multas legais ou quebra um SLA contratual penalizador.
Integridade de Dados Críticos: Onde a perda de dados viola o RPO aceitável (ex: sistemas de retenção de dados obrigatórios).
O resto? Pode ser restaurado via um recovery playbook bem definido. Jobs batch, sistemas internos de retaguarda, e dashboards podem tolerar minutos (ou até horas) de inatividade — desde que o plano de reprocessamento seja claro.
Alta disponibilidade sem propósito é como instalar um airbag em uma bicicleta. É uma solução sofisticada para um problema que não existe naquele contexto.
5. Gerenciado != Isento de Falhas: A Mentalidade Serverless
Um erro comum é acreditar que usar serviços serverless (Lambda, DynamoDB, SQS, EventBridge) é sinônimo de imunidade a falhas. Não é.
A falha vai vir — e, com frequência, de onde você menos espera, pois o paradigma serverless muda a superfície de risco.
O ponto chave é:
Serviços gerenciados reduzem a superfície operacional (você não gerencia OS, patching ou capacidade), mas não substituem o bom design e preparo.
Durante o outage de us-east-1 em outubro de 2025, muitas aplicações 100% serverless ficaram indisponíveis. Não porque o serverless falhou — mas porque dependiam de uma única região. Quando a resolução de DNS do endpoint regional do DynamoDB quebrou, tudo que estava preso ao us-east-1 (direto, ou indireto via um control plane global como IAM ou STS) quebrou junto. Multi-AZ não teria salvado: o endpoint era regional, não zonal. E as aplicações que demoraram mais a se recuperar eram, com frequência, as que respondiam à falha com retries agressivos e sem limite — transformando um outage em um retry storm autoinfligido.
A Resiliência Real não vem da AWS. Vem da Arquitetura que você desenha em cima dela.
6. A Decisão é do Negócio — A Clareza é do Arquiteto
A diferença entre "ter opinião" e "ter influência" está em sua capacidade de traduzir a complexidade técnica em clareza estratégica. Seu papel não é assustar o board com jargões, mas sim dar a eles a visibilidade necessária para decidir com consciência.
Minha experiência me ensinou que a maturidade de um time pode ser medida justamente por essa habilidade de fazer a pergunta certa:
❓ Onde está a Maturidade do Seu Time?
Times Imaturos Focam na Ferramenta:
Perguntam: "Qual stack resolve isso?"
Perguntam: "Devemos usar K8S ou Serverless?"
Perguntam: "O que a Netflix faz?"
Times Maduros Focam no Risco e no Negócio:
Perguntam: "Qual risco estamos dispostos a aceitar por esse custo?"
Perguntam: "Qual é o RTO/RPO que o cliente final exige deste serviço?"
Perguntam: "O que o nosso negócio precisa para sobreviver a um desastre?"
O resultado é que dois times podem usar exatamente a mesma CLOUD — um escala com previsibilidade, o outro vive em modo pânico. A diferença não é a cloud. É o nível de entendimento, documentação e humildade técnica sobre as decisões tomadas.
A Armadilha Comum: Quem nunca ouviu de um executivo: "Decisões técnicas são com o time de Arquitetura"? Ele está, na verdade, transferindo a responsabilidade pela definição do risco de negócio. Seu time define o COMO (a stack), mas o Negócio define o QUANTO (o RTO e o RPO aceitáveis). É seu papel devolver a pergunta para que a decisão de risco seja do negócio.
Traduzindo Conceitos de Resiliência para a Liderança:
(Afinal, quem nunca ouviu: “Agora traduz isso pra eu entender!”)
1. Failover Multi-Region
Tradução: O seguro contra a catástrofe. Garante que um desastre
regional não nos tire do ar por dias, reduzindo o
prejuízo de receita a poucas horas.
Pergunta: Quantas horas (ou minutos) de downtime o negócio pode
aceitar no serviço X, caso a região inteira caia?
------------------------------------------------------------------
2. Active-Active Setup
Tradução: Disponibilidade máxima e ininterrupta. Permite que
façamos qualquer manutenção ou atualização sem jamais
impactar o cliente final.
Pergunta: O serviço X precisa estar 100% contínuo? Podemos ter
um período de 15 minutos de downtime para manutenção?
------------------------------------------------------------------
3. RTO / RPO
Tradução: Definindo o Limite do Prejuízo. São os números que
nos dizem o que e por quanto tempo podemos perder antes
que as multas ou a reputação se tornem insustentáveis.
Pergunta: Quantos dados (RPO) podemos perder e quanto tempo (RTO)
o time tem para restaurar o serviço sem que o negócio quebre?
------------------------------------------------------------------
4. SPOF (Single Point of Failure)
Tradução: O Calcanhar de Aquiles da Receita. É o ponto fraco que,
se quebrado, paralisa a empresa inteira. É onde o risco
deve ser zero.
Pergunta: Se este componente cair, qual é o prejuízo financeiro
em 1 hora?
7. Conclusão
Não existe arquitetura à prova de falhas.
Mas existe organização à prova de surpresas.
E ela começa com decisões conscientes, documentação (os ADRs), e a humildade técnica de aceitar que o erro e o risco fazem parte da equação.
Times que entendem o "porquê" antes de se aprofundarem no "como" constroem sistemas que não apenas escalam, mas que, acima de tudo, sobrevivem — e crescem com previsibilidade.
8. Referências Essenciais
Para quem deseja aprofundar as decisões de risco e os padrões arquiteturais, estes são os documentos que usamos como base para a resiliência em qualquer cloud (com foco em AWS):
AWS Well-Architected Framework – Reliability Pillar: O guia fundamental para entender os princípios de recuperação de desastres (DR) e alta disponibilidade (HA). Guia de Confiabilidade (Reliability Pillar)
Disaster Recovery of Workloads on AWS: Documento-chave para aprofundar RTO/RPO e escolher entre padrões como Pilot Light e Active-Active. Whitepaper de DR
DynamoDB Global Tables: Um excelente estudo de caso prático de HA a nível de dados, que abstrai a complexidade do multi-region. Documentação do DynamoDB Global Tables
EventBridge Resilience Guide: Essencial para quem trabalha com serverless, focando em padrões de resiliência baseados em eventos. Guia de Resiliência do EventBridge
9. Glossário Essencial para Resiliência
Para que todos estejam na mesma página, aqui estão alguns termos-chave utilizados neste artigo, explicados de forma simples:
Alta Disponibilidade (HA): É a capacidade de um sistema continuar operando mesmo quando um ou mais de seus componentes falham. Medimos em "9s" (ex: 99,99%).
Outage: Uma interrupção não planejada de um serviço, ou seja, o serviço fica fora do ar.
On-premise: Infraestrutura e data centers próprios que estão fisicamente no local da empresa (não na nuvem).
Multi-Região: Usar data centers em duas ou mais regiões geográficas diferentes da nuvem (ex: Leste dos EUA e São Paulo) para máxima proteção contra desastres regionais.
Multi-AZ (Multi-Availability Zone): Usar duas ou mais Zonas de Disponibilidade (datacenters isolados e próximos) dentro da mesma região da nuvem. É o padrão básico de HA.
SLA (Service Level Agreement): Um acordo formal que define o nível de serviço esperado de um fornecedor para um cliente (geralmente medido em tempo de uptime).
ROI (Retorno Sobre o Investimento): Uma métrica financeira que mede a relação entre o dinheiro ganho (ou economizado) e o dinheiro investido.
ADR (Architecture Decision Record): Documento curto que registra uma decisão arquitetural, o motivo e o risco aceito em um ponto específico do tempo.
RTO (Recovery Time Objective): O tempo máximo aceitável que um sistema pode ficar fora do ar após uma falha.
RPO (Recovery Point Objective): A quantidade de dados (medida em tempo, ex: 5 minutos) que pode ser perdida durante um evento de desastre.
Serverless: Um modelo de computação em nuvem onde o provedor gerencia toda a infraestrutura, e o desenvolvedor se foca apenas no código, pagando apenas pelo uso.
Circuit Breaker: Um padrão de software que, quando um serviço dependente começa a falhar repetidamente, "abre" o circuito, protegendo o restante da aplicação de falhas em cascata.
Resumo Pós-Evento da AWS — Amazon DynamoDB Service Disruption na região US-EAST-1 (19–20 de outubro de 2025): a fonte primária e oficial sobre o outage citado neste artigo, com o post-mortem completo da causa-raiz e da cascata de falhas. Resumo da Interrupção
💡 Quer aprofundar esse debate sobre resiliência, orquestração e o papel estratégico do desenvolvedor na era serverless?
Estarei no ServerlessDays São Paulo, no dia 8 de novembro, no Cubo Itaú, falando exatamente sobre como ir além da simples stack e construir sistemas que não apenas funcionam, mas prosperam no caos. Te vejo lá!