AWS MCP Server: qual usar, quando e como configurar (os dois servidores explicados)
Knowledge MCP x AWS MCP gerenciado, IAM e o passo a passo pra conectar no Kiro e no Claude Code sem colar access key no `.env`.

Staff Engineer @Serverless Guru | AWS Community Builder | Specialist in Serverless, AWS & Event-Driven Architectures | Speaker & Content Creator @willpeixoto.dev
Knowledge MCP x AWS MCP gerenciado, IAM e o passo a passo pra conectar no Kiro e no Claude Code sem colar access key no
.env.
Deixa eu te contar uma cena. Aposto que você já viveu ela.
São 11 da noite, você tá de boas codando com a ajuda de uma IA do lado. Você faz uma pergunta pra ela e ela jura que existe: inventa um serviço, um nome que bate com algo parecido que você já fez, e até uma implementação que ela garante que funciona, com tudo e como resolver. E você pensa: caramba, não sabia disso, preciso olhar melhor a documentação porque faz muito sentido. E bang, você descobre que ela tava alucinando. Tava escrevendo código na Lambda chamando um serviço da AWS de uma função que não existe, ligando a tabela do DynamoDB, montando o IaC, tudinho. Aí ela pede pra "dar uma olhada na config atual da sua conta" pra validar os nomes, e você bate na parede que todo mundo bate.
O agente, além de alucinar, não tem acesso à sua conta. Ele não enxerga seus recursos, não faz ideia do que realmente tá lá. E faz o que ele faz de melhor: é criativo, é proativo, e inventa algo pra te deixar feliz. Pra ele, aquilo faz sentido existir, então ele assume que existe. O bichinho não fica nem com vergonha: na maior cara de pau, devolve um ARN que não existe, escolhe uma região que você nem usa e chuta o nome de uma tabela. Dá-lhe. Ele tá fazendo exatamente o que foi programado pra fazer: te deixar feliz.
E você, cansado de brigar com ele e já querendo finalizar, faz o quê? Cola uma access key num .env pra ele "só enxergar a conta um segundinho" e te devolver tudo certinho, com os nomes verdadeiros. Quem nunca?
E tá tudo bem, só que tem um detalhe: você esquece que fez isso. E bang, o .env foi junto no commit. Já tá no histórico do git, alerta pra todo lado, aquela doideira de sempre. Pronto, a chave tá exposta. E é assim também que o seu agente, naquele momento em que parece que quer te punir ou que resolveu ser proativo demais, ganha acesso de verdade à sua conta e, sei lá, decide apagar a stack errada. Ou então é só a continha surpresa de R$ 40 num dia, que vira um número bem pior quando ninguém tá olhando. Eu já passei por isso. Você provavelmente também.
A boa notícia é que a AWS resolveu esse problema. Na real, resolveu de duas formas diferentes, com nomes tão parecidos que confunde muita gente. Esse post é o mapa que eu queria ter tido: o que são os dois, qual dor cada um mata, e quando e como usar cada. Vamos lá.
O que você vai sair sabendo
Pra você não se perder, é isso que a gente cobre aqui:
A diferença entre os dois servidores MCP da AWS e qual dor cada um resolve
Como conectar os dois no Kiro e no Claude Code, passo a passo
Como configurar o IAM da sua conta pra dar acesso com segurança
Quando NÃO usar, e os cuidados pra não tomar susto na conta
Mas o que é MCP afinal?
Antes de falar dos servidores, vamos nivelar.
O MCP (Model Context Protocol) é o "plugue" que o seu assistente de IA usa pra falar com o mundo lá fora: ferramentas, dados e serviços. A Anthropic criou, hoje ele tá sob governança aberta, e no último ano todo assistente que presta (Claude Code, Kiro, Cursor) passou a falar MCP.
Quer uma analogia fácil? Pensa na API. A API é o que deixa duas aplicações conversarem entre si. O MCP é a mesma ideia, só que pro agente: é o que deixa a IA conversar com qualquer ferramenta sem você ter que criar uma integração personalizada pra cada sistema diferente. O MCP conecta o agente ao sistema num padrão que todo mundo combinou de usar. E o bom de ser padrão é esse: você aprende uma vez e serve pra qualquer ferramenta e qualquer cliente. Então, se você quer dar acesso ao seu sistema pra uma IA, é por esse caminho que você vai.
E tem uma coisa que facilita demais: na maioria dos casos, você nem precisa construir um MCP server seu. Dá pra construir, claro (rodando no Lambda, no Fargate, no que você preferir), e a AWS até tem um guidance oficial pra isso se for o seu caso. Mas a AWS já roda servidores gerenciados prontos, então muita vez é só plugar e usar.
Os dois servidores MCP da AWS
Pois é, são dois. E os nomes não ajudam em nada, viu. Olha tudo numa tabela só e depois eu destrincho cada um:
| AWS Knowledge MCP Server | AWS MCP Server (gerenciado, GA) | |
|---|---|---|
| Que dor resolve | "Meu agente alucina API, ARN e nome de serviço da AWS." | "Meu agente precisa ver ou agir na minha conta, sem eu vazar chave." |
| O que acessa | Só documentação e conhecimento da AWS (read-only) | Documentação + serviços reais da sua conta (autenticado) |
| Credenciais | Nenhuma. Nem conta AWS você precisa. | Credenciais locais da AWS CLI (IAM / SigV4) |
| Auditoria | Não se aplica | CloudTrail + CloudWatch |
| Use quando | Quer sintaxe certa, docs atuais, disponibilidade regional | Quer o agente inspecionando ou operando infra real |
| Risco se usar errado | Praticamente zero | Real. É a sua conta. Least-privilege importa. |
Se você guardar uma frase só desse post, guarda essa:
Um servidor dá conhecimento pro seu agente. O outro dá mãos pra ele.
Sacar qual problema você tem de verdade já é metade do caminho.
Quer outra analogia? O Knowledge é o guru: aquele amigo que decorou a documentação inteira da AWS e tira sua dúvida na hora. Já o gerenciado é o porteiro cara-crachá: ele te deixa entrar na conta de verdade, mas fica ali conferindo e só abre as portas que o IAM autorizou. Cara, crachá. Não bateu, não passa.
Servidor #1: AWS Knowledge MCP Server
O que esse servidor faz é simples: é remoto, totalmente gerenciado, e dá ao modelo acesso estruturado à documentação oficial, sempre atualizada. E esse "atualizada" é o ponto. O que o modelo sabe sozinho para na data de treino dele, então ele não conhece o que veio depois e acaba chutando. A AWS mantém esse servidor em dia, então ele vira a sua fonte da verdade: busca na doc, traz a página em markdown limpo, checa se um serviço existe numa região e lista as regiões atuais. Só leitura, não escreve nem toca na conta.
Por que é quase óbvio ligar? Porque não tem credencial, e nem conta AWS é necessária. Não tem nada pra proteger, nada pra vazar. O risco é praticamente zero e o ganho é o agente parar de chutar e começar a citar a doc real antes de cuspir o CDK.
Use quando você tá aprendendo um serviço, desenhando a arquitetura que quer construir e validando a ideia, conferindo sintaxe, gerando IaC em que você confia, ou respondendo "isso já tá na minha região?" sem precisar abrir o navegador. Com ele no ar (mostro como ligar logo abaixo, na seção de conexão), o agente consulta a doc live antes de cuspir o CDK em vez de chutar pelo que viu no treino. ARN alucinado despenca. Legal não?
Servidor #2: AWS MCP Server, o gerenciado (que lê e opera a conta)
Esse aqui é o que cura a vergonha do .env.
A dor é outra: o agente precisa ver ou fazer algo na conta de verdade. Ler o log do CloudWatch da função que tá quebrando, listar o que realmente tem no bucket, conferir o schema da tabela do DynamoDB. A "solução" antiga era entregar credencial de longa duração pra ele. É essa parte que tira o sono do pessoal de segurança. E, sinceramente, devia tirar o seu também.
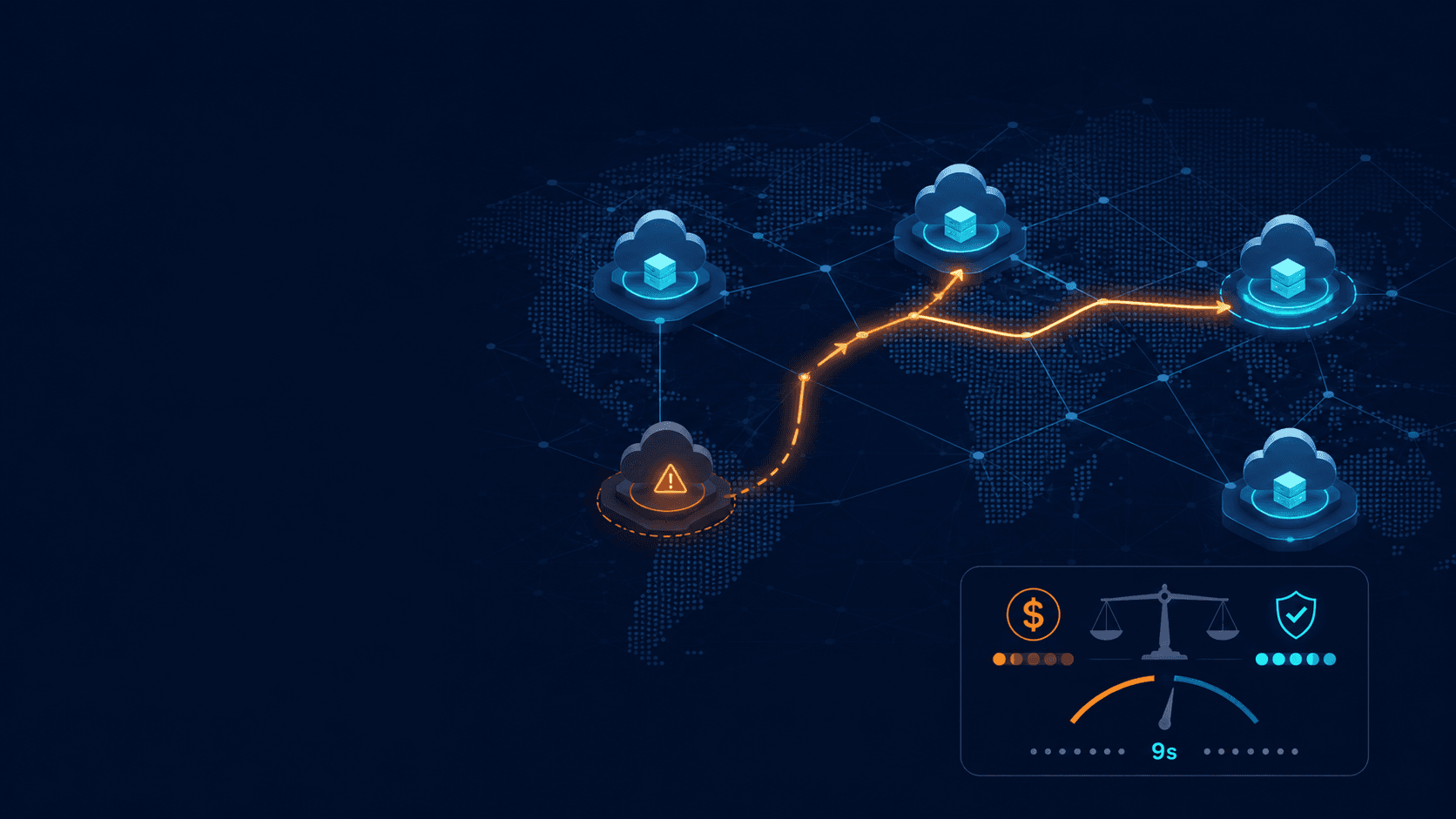
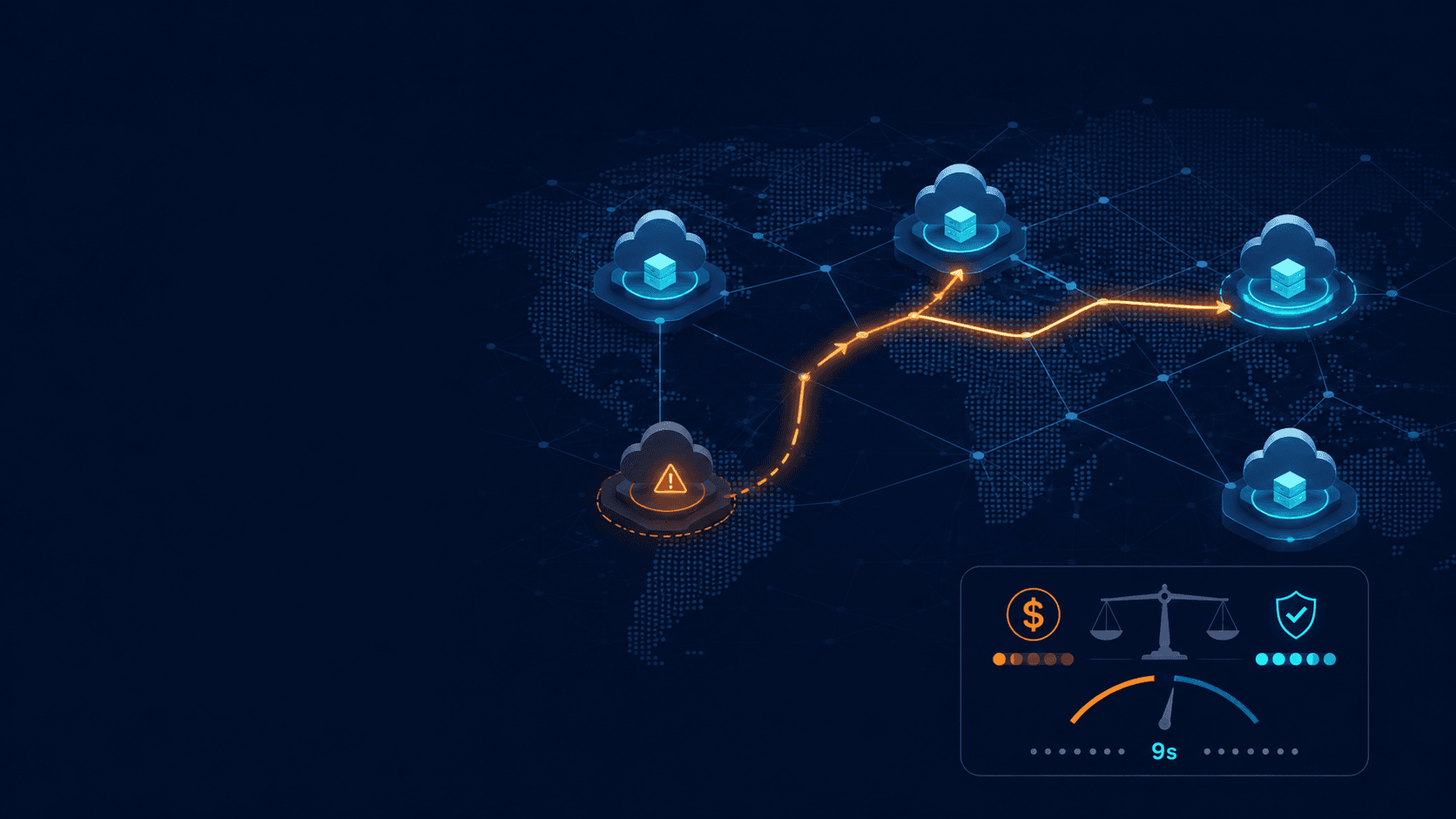
O que esse servidor faz: ele é remoto, hospedado e gerenciado pela AWS, e dá ao agente acesso autenticado aos serviços da AWS através de um conjunto pequeno e fixo de ferramentas. Sem instalação local, com update automático, e (essa parte eu curto demais) toda chamada vai parar no CloudTrail. O agente não ganha uma chave-mestra. Ele se autentica como você, por um fluxo de auth de verdade, com a coleira do IAM.
O fluxo de auth, em bom português: o endpoint do servidor usa IAM com SigV4, não OAuth direto. Como cliente MCP só fala OAuth, entra em cena o mcp-proxy-for-aws, um proxy open source que roda na sua máquina e faz a ponte. Ele pega as suas credenciais locais da AWS CLI e assina as chamadas com SigV4. Resultado: você não cola chave em lugar nenhum, o agente age com a sua identidade de sempre, e tudo respeita o seu IAM. Busca na documentação, aliás, nem credencial precisa.
Visualmente, o fluxo é esse:

O momento "aaah, sacou" é esse: pergunta "por que o checkout-prod começou a dar 500 depois das 14h?" e vê o agente puxar o log real do CloudWatch, cruzar com um deploy recente e apontar o recurso de verdade. Tudo dentro do que o IAM permite, tudo auditável, sem chave em dotfile nenhum. E funciona com o que você já usa: Claude Code, Kiro, Cursor, qualquer cliente compatível com MCP.
Como conectar no Kiro e no Claude Code
Agora a parte prática, pros dois clientes que mais bombam hoje. Em ambos é a mesma lógica: o aws-knowledge é HTTP público (liga na hora), e o aws gerenciado roda pelo mcp-proxy-for-aws (precisa do uv instalado e da AWS CLI logada com aws login; sem login no navegador).
No Kiro
O Kiro lê os MCP servers de um arquivo mcp.json: por projeto, em <raiz>/.kiro/settings/mcp.json, ou global, em ~/.kiro/settings/mcp.json (vale pra todo projeto; quando os dois existem, o do projeto ganha). Eu deixaria o aws-knowledge no global e o aws por projeto:
{
"mcpServers": {
"aws-knowledge": {
"type": "http",
"url": "https://knowledge-mcp.global.api.aws",
"disabled": false
},
"aws": {
"command": "uvx",
"args": [
"mcp-proxy-for-aws@latest",
"https://aws-mcp.us-east-1.api.aws/mcp",
"--metadata", "AWS_REGION=sa-east-1"
]
}
}
}
Só que config liga o server, não garante que o Kiro vá usar. Pra ele preferir essas ferramentas, cria um steering file em .kiro/steering/aws-mcp.md:
---
inclusion: always
---
# Uso de AWS via MCP
- Antes de gerar código ou IaC de AWS (CDK, CloudFormation, SDK), consulte o
`aws-knowledge` MCP pra validar nome de serviço, sintaxe e disponibilidade na
região. Não chute API nem ARN.
- Pra inspecionar recursos reais da conta (logs do CloudWatch, itens do S3,
schema do DynamoDB), use o server `aws`. Nunca peça nem use access key.
- Nunca rode ação destrutiva (delete, scaling) sem confirmar antes.
O inclusion: always faz essa regra entrar em toda conversa do Kiro naquele projeto.
No Claude Code
O aws-knowledge entra com uma linha:
claude mcp add --transport http aws-knowledge https://knowledge-mcp.global.api.aws
O aws gerenciado vem no Agent Toolkit for AWS. O mais fácil é como plugin, em dois passos no mesmo agente: primeiro você registra o marketplace (a fonte dos plugins), depois instala o plugin a partir dele.
/plugin marketplace add aws/agent-toolkit-for-aws # registra a fonte (uma vez)
/plugin install aws-core@agent-toolkit-for-aws # instala o plugin
Prefere na mão? Dá pra adicionar via proxy:
claude mcp add-json aws-mcp --scope user '{"command":"uvx","args":["mcp-proxy-for-aws==1.6.0","https://aws-mcp.us-east-1.api.aws/mcp","--metadata","AWS_REGION=sa-east-1"]}'
O endpoint é regional (hoje us-east-1 e eu-central-1); você conecta no us-east-1 e opera nos recursos da região que passar em AWS_REGION. Confere o atual na doc oficial, que isso pode mudar. O equivalente do steering aqui é um CLAUDE.md na raiz do projeto, com as mesmas regras.
A parte de segurança que você não pode ignorar
"Everything fails, all the time."
Werner Vogels, CTO da Amazon
Se tem uma parte pra não pular, é essa. O Werner tá certo, e com uma IA pilotando a sua conta vale levar a frase ao pé da letra: parte do princípio de que uma hora o agente vai aprontar, e projete pra isso. Dar acesso pra ele ler e operar a conta é tão sério quanto parece, então vale fazer com cuidado.
Primeira coisa: o IAM continua sendo o chefe. O servidor gerenciado não passa por cima das suas permissões, ele anda em cima delas. Trate o agente como um colega de trabalho novo. Ou melhor: como aquele estagiário recém-formado que faz tudo ao pé da letra, sem questionar, e que, com medo de fazer errado, nem para pra pensar. É o tipo que, se você mandar procurar o estoque de faísca pra guardar numa garrafa, ele sai atrás de boa. Pois é, o agente é assim também: se você der acesso demais, ele usa, mesmo quando não faz o menor sentido. Por isso, least-privilege, escopado só pro que a tarefa precisa, e nada além disso. A AWS criou context keys de IAM padronizadas pra esses servidores MCP gerenciados, então dá pra escrever policy que sabe "essa chamada veio pelo MCP server" e restringir de acordo.
Segunda: não tem chave de longa duração em lugar nenhum. O proxy assina com as suas credenciais temporárias da AWS CLI, que giram sozinhas (a cada uns 15 minutos). Ou seja, não sobra segredo parado no seu histórico de shell, no repo ou no .env, que é exatamente onde a gente costuma vazar.
Terceira: tudo é auditável. O CloudTrail loga cada chamada e o CloudWatch te dá as métricas. Depois de um incidente, você responde "o que o agente fez, afinal?" de cara limpa. Se hoje você não consegue responder isso sobre o seu setup atual, só isso já é motivo de sobra pra trocar.
E uma que ainda tá chegando: suporte a VPC endpoint, pra quem precisa manter esse tráfego dentro da fronteira da rede. Se isso é requisito duro pra você, espera por ele antes de levar pra produção.
Minha regra de bolso? Uma role de IAM dedicada por propósito de agente. Se um agente for comprometido ou der ruim, o estrago para naquela role. Não reusa sua identidade de admin. E não dá * em * "só pra destravar a demo", porque a demo vira prod mais rápido do que você imagina.
Configurando o lado da SUA conta AWS (o essencial)
Do lado da conta é menos coisa do que parece, porque o AWS MCP Server gerenciado não cria ações de IAM próprias. Não existe mcp:Invoke pra liberar: ele assina cada chamada com SigV4 usando as suas credenciais e encaminha pro serviço, que autoriza pelas suas policies de sempre. Se a sua identidade não pode chamar logs:GetLogEvents, o agente também não pode. As suas permissões atuais são a fronteira.
O quick-start é esse: comece com uma identidade read-only (uma role dedicada ou um permission set de SSO) e use as context keys novas, aws:ViaAWSMCPService e aws:CalledViaAWSMCP, pra negar ação destrutiva quando a chamada vier do agente, mesmo que a sua role pudesse fazer. Assim o agente lê à vontade e os verbos perigosos ficam bloqueados só pra ele. Depois, deixa o CloudTrail mostrar o que ele realmente usou e aperta a policy em cima disso.
Um guardrail simples, só pra você pegar a ideia:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "BlockDestructiveActionsViaMCP",
"Effect": "Deny",
"Action": ["dynamodb:DeleteTable", "s3:DeleteBucket", "lambda:DeleteFunction"],
"Resource": "*",
"Condition": { "Bool": { "aws:ViaAWSMCPService": "true" } }
}]
}
Esse setup merece um post só dele, feito como código. Vou soltar em seguida um "IAM pra agente de IA na AWS, com CDK" com o passo a passo completo (CLI, console e CDK), cdk-nag, SCP org-wide e multi-conta. Quando sair, linko aqui.
Qual dos dois usar: a decisão de 10 segundos
Só precisa que ele acerte a AWS (sintaxe, serviço, região)? Vai de Knowledge: liga, sem credencial, toca o barco. Precisa que ele leia ou mude algo na sua conta? Vai de gerenciado, escopado com IAM.
E aqui um detalhe que muda a conta: o gerenciado já inclui a busca na documentação, sem credencial, e a AWS o trata como sucessor do Knowledge. Ou seja, você não precisa rodar os dois. O Knowledge continua ótimo pra quando você quer só consultar doc, sem credencial e sem instalar nada.
Quando NÃO usar isso
Porque não existe bala de prata, e alguém tem que falar.
Não solta isso numa conta de produção sem guardrail. Começa num sandbox e acerta as fronteiras de IAM antes do agente poder tocar em qualquer coisa que cobra ou apaga. No Frugal Architect, o Werner prega que custo é requisito de arquitetura, não algo pra descobrir no fim do mês, e com um agente disparando chamada isso vale dobrado.
Não libera permissão larga "por enquanto". Não existe "por enquanto", confia em mim. Escopa desde a primeira conexão.
E não deixa coisa irreversível no automático. Delete, ação de scaling, movimentação de dinheiro: mantém humano no loop. O agente propõe, você aprova.
Recorte Brasil
Três pontos que importam pra quem opera aqui em São Paulo.
O primeiro é a região sa-east-1. Antes de apontar o agente, confirma a disponibilidade dos serviços e do servidor gerenciado na região de São Paulo. E olha que beleza: essa é literalmente uma pergunta que o Knowledge MCP Server responde pra você. Vale checar em vez de assumir.
O segundo é LGPD e residência de dado. Se o agente vai tocar em recurso com dado pessoal, escopa o IAM pra ele não conseguir ler o que não deve, e usa a trilha do CloudTrail como evidência de quem acessou o quê. Auditabilidade aqui não é só boa prática técnica, é argumento de conformidade.
O terceiro é auditoria pra time pequeno. Esse CloudTrail "de graça" é ouro pra quem não tem um time de segurança dedicado. Você ganha o registro de tudo que o agente fez sem montar nada.
Pra fechar
São dois servidores MCP da AWS pra duas dores: conhecimento (parar de alucinar) e ação (operar a conta com segurança).
O Knowledge não tem credencial nem risco. Liga hoje, sério.
O gerenciado te tira do
.env: usa as suas credenciais temporárias da AWS CLI (IAM/SigV4) no lugar de segredo de longa duração, com least-privilege e tudo logado no CloudTrail.Não precisa rodar os dois: o gerenciado já faz busca na doc e é o sucessor do Knowledge. Use o Knowledge pra docs sem credencial; o gerenciado pro pacote completo (docs + conta). Se você vinha fazendo a gambiarra do
.env, relaxa, todo mundo já fez. Mas as ferramentas pra parar tão aqui, são gerenciadas e são auditáveis. Não tem mais desculpa boa pra continuar entregando as chaves da sua conta pra um robô que de vez em quando viaja na maionese.
Esse post abre uma série sobre MCP e agentes na AWS. Nos próximos eu vou fundo em dois caminhos: configurar o IAM como código (CDK) e a OpenAI chegando no Bedrock. Qual você quer primeiro? Comenta aí.
Curtiu? Manda aquele joinha, comenta o que você achou e compartilha com a galera pra fortalecer. Valeu demais por ler até aqui! =D
Pra ir mais fundo
Os MCP servers open source da AWS (awslabs/mcp), onde vive o Knowledge MCP Server
Agent Toolkit for AWS, de onde vem o AWS MCP Server gerenciado