AWS MCP Server: which one to use, when, and how to set it up (the two servers explained)
Knowledge MCP vs the managed AWS MCP Server, IAM, and the step by step to connect it in Kiro and Claude Code without pasting an access key into your `.env`.

Staff Engineer @Serverless Guru | AWS Community Builder | Specialist in Serverless, AWS & Event-Driven Architectures | Speaker & Content Creator @willpeixoto.dev
Let me tell you a scene. I bet you've lived it.
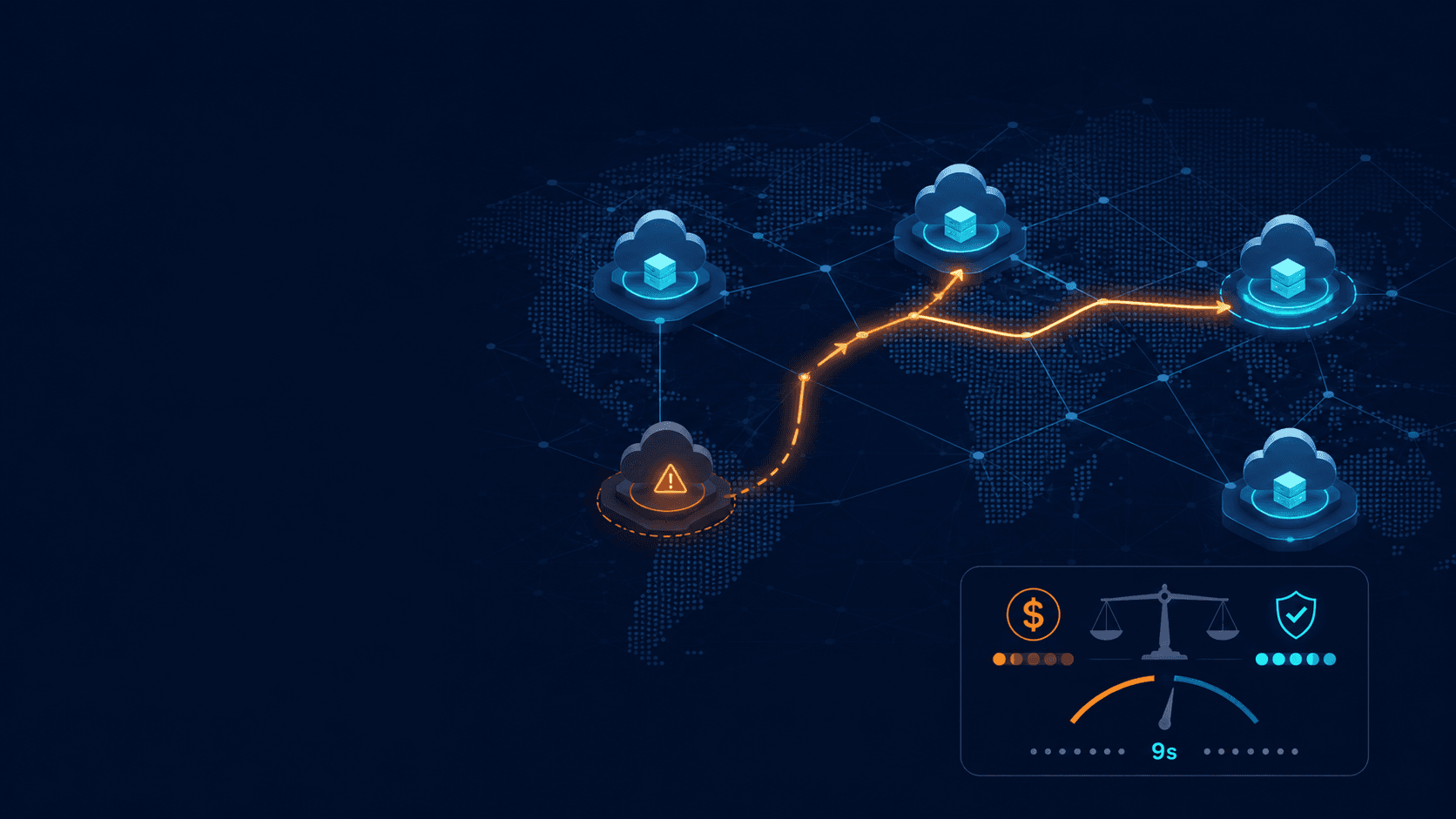
It's 11pm, you're coding with an AI sitting right next to you. You ask it something and it swears the thing exists: it makes up a service, a name that sounds a lot like something you've built before, even an implementation it promises works, with the full how-to. And you think: huh, didn't know that one, let me check the docs because it makes total sense. And bang, you find out it was hallucinating. It was writing Lambda code calling an AWS service from a function that doesn't exist, wiring up the DynamoDB table, building the IaC, the whole thing. Then it asks to "take a look at your account's current config" to validate the names, and you hit the wall everyone hits.
The agent, besides hallucinating, has no access to your account. It can't see your resources, it has no idea what's actually there. So it does what it does best: it's creative, it's proactive, and it invents something to make you happy. To it, that thing makes sense to exist, so it assumes it exists. The little guy doesn't even blush: it hands you an ARN that doesn't exist, picks a region you don't use, and guesses a table name. There it goes. It's doing exactly what it was built to do, which is make you happy.
And you, tired of fighting with it and just wanting to wrap up, do what? You paste an access key into a .env so it can "just see the account for a second" and give you everything right, with the real names. Who's never done that?
And it's all fine, except for one detail: you forget you did it. And bang, the .env went along in the commit. It's already in the git history, alerts firing everywhere, the usual mess. The key is exposed now. And that's also how your agent, in that moment where it seems to want to punish you or decided to be a little too proactive, gets real access to your account and, who knows, decides to delete the wrong stack. Or it's just the surprise bill of forty bucks in a single day, which turns into a much worse number when nobody's watching. I've been through this. You probably have too.
The good news is that AWS solved this. Actually, it solved it two different ways, with names so similar they confuse a lot of people. This post is the map I wish I'd had: what the two are, which pain each one kills, and when and how to use each. Let's go.
What you'll walk away knowing
So you don't get lost, here's what we cover:
The difference between the two AWS MCP servers and which pain each one solves
How to connect both in Kiro and Claude Code, step by step
How to set up your account's IAM to grant access safely
When NOT to use it, and how to avoid a nasty surprise on your bill
But what is MCP, anyway?
Before talking about the servers, let's level set.
MCP (Model Context Protocol) is the "plug" your AI assistant uses to talk to the outside world: tools, data and services. Anthropic created it, it's under open governance now, and over the last year every assistant worth using (Claude Code, Kiro, Cursor) started speaking MCP.
Want an easy analogy? Think about the API. The API is what lets two applications talk to each other. MCP is the same idea, just for the agent: it's what lets the AI talk to any tool without you having to build a custom integration for every single system. MCP connects the agent to the system through a standard everyone agreed to use. And that's the nice thing about a standard: you learn it once and it works for any tool and any client. So if you want to give an AI access to your system, this is the path to follow.
And here's something that makes life a lot easier: for most cases, you don't even need to build your own MCP server. You can build one, sure (on Lambda, on Fargate, whatever you prefer), and AWS even has an official guidance for that if that's your case. But AWS already runs managed servers ready to go, so a lot of the time you just plug in and use it.
The two AWS MCP servers
Yep, there are two. And the names don't help at all. Here's everything in one table, then I break down each one:
| AWS Knowledge MCP Server | AWS MCP Server (managed, GA) | |
|---|---|---|
| What it solves | "My agent hallucinates AWS APIs, ARNs and service names." | "My agent needs to see or act on my account, without me leaking a key." |
| What it accesses | Only AWS docs and knowledge (read-only) | Docs + real services in your account (authenticated) |
| Credentials | None. You don't even need an AWS account. | Local AWS CLI credentials (IAM / SigV4) |
| Audit | Not applicable | CloudTrail + CloudWatch |
| Use it when | You want correct syntax, current docs, regional availability | You want the agent inspecting or operating real infra |
| Risk if misused | Basically zero | Real. It's your account. Least-privilege matters. |
If you keep one sentence from this post, keep this one:
One server gives your agent knowledge. The other gives it hands.
Figuring out which problem you actually have is half the battle.
Want another analogy? The Knowledge server is the guru: that friend who memorized the entire AWS documentation and clears up your doubt on the spot. The managed one is the doorman checking badges: it lets you into the account for real, but it stands there checking and only opens the doors IAM authorized. Name doesn't match the badge? You don't get in.
Server #1: AWS Knowledge MCP Server
What this server does is simple: it's remote, fully managed, and it gives the model structured access to the official docs, always current. And that "current" is the point. What the model knows on its own stops at its training date, so it has no clue about what came after and ends up guessing. AWS keeps this server in sync, so it becomes your source of truth: it searches the docs, returns the page as clean markdown, checks whether a service exists in a region, and lists the current regions. Read-only, it doesn't write or touch the account.
Why is it almost a no-brainer to turn on? Because there's no credential, and no AWS account needed. Nothing to protect, nothing to leak. The risk is basically zero and the payoff is the agent stops guessing and starts citing the real docs before it spits out the CDK.
Use it when you're learning a service, designing the architecture you want to build and validating the idea, checking syntax, generating IaC you actually trust, or answering "is this in my region yet?" without opening the browser. With it on (I'll show how to connect below), the agent checks the live docs before spitting out the CDK instead of guessing from training. Hallucinated ARNs drop off a cliff. Pretty good, right?
Server #2: AWS MCP Server, the managed one (reads and operates the account)
This is the one that cures the .env shame.
The pain is different: the agent needs to see or do something in the account for real. Read the CloudWatch logs of the function that's breaking, list what's actually in the bucket, check the real schema of the DynamoDB table. The old "solution" was to hand it a long-lived credential. That's the part that keeps the security folks up at night. And honestly, it should keep you up too.
What this server does: it's remote, hosted and managed by AWS, and it gives the agent authenticated access to AWS services through a small, fixed set of tools. No local install, automatic updates, and (this part I really like) every call lands in CloudTrail. The agent doesn't get a master key. It authenticates as you, through a real auth flow, on an IAM leash.
The auth flow in plain English: the server's endpoint uses IAM with SigV4, not OAuth directly. Since an MCP client only speaks OAuth, the mcp-proxy-for-aws steps in, an open source proxy that runs on your machine and bridges the two. It takes your local AWS CLI credentials and signs the calls with SigV4. The result: you don't paste a key anywhere, the agent acts with your usual identity, and everything respects your IAM. Documentation search, by the way, needs no credentials at all.
Here's the flow, step by step:

You run
aws login(local creds) and connect the server in your client.The agent fires an MCP call.
mcp-proxy-for-awssigns it with SigV4 (your creds) and forwards it to the AWS MCP Server.The server applies the context keys and passes it to the AWS service.
IAM authorizes via your policy and responds.
The whole call is logged to CloudTrail.
The "ohhh, got it" moment is this: ask "why did checkout-prod start throwing 500s after 2pm?" and watch the agent pull the real CloudWatch logs, cross-reference a recent deploy, and point at the actual resource. All inside what IAM allows, all auditable, with no key in any dotfile. And it works with what you already use: Claude Code, Kiro, Cursor, any MCP-compatible client.
How to connect in Kiro and Claude Code
Now the practical part, for the two clients trending the most. Same logic in both: aws-knowledge is public HTTP (connects right away), and the managed aws runs through mcp-proxy-for-aws (needs uv installed and the AWS CLI logged in with aws login; no browser login).
In Kiro
Kiro reads MCP servers from an mcp.json file: per project, in <root>/.kiro/settings/mcp.json, or global, in ~/.kiro/settings/mcp.json (applies to every project; when both exist, the project one wins). I'd keep aws-knowledge global and the aws one per project:
{
"mcpServers": {
"aws-knowledge": {
"type": "http",
"url": "https://knowledge-mcp.global.api.aws",
"disabled": false
},
"aws": {
"command": "uvx",
"args": [
"mcp-proxy-for-aws@latest",
"https://aws-mcp.us-east-1.api.aws/mcp",
"--metadata", "AWS_REGION=sa-east-1"
]
}
}
}
But config only turns the server on, it doesn't guarantee Kiro will use it. To make it prefer these tools, create a steering file at .kiro/steering/aws-mcp.md:
---
inclusion: always
---
# Using AWS via MCP
- Before generating any AWS code or IaC (CDK, CloudFormation, SDK), check the
`aws-knowledge` MCP to validate service names, syntax and regional
availability. Don't guess APIs or ARNs.
- To inspect real account resources (CloudWatch logs, S3 items, DynamoDB
schema), use the `aws` server. Never ask for or use an access key.
- Never run a destructive action (delete, scaling) without confirming first.
inclusion: always makes that rule part of every Kiro conversation in that project.
In Claude Code
aws-knowledge is a one-liner:
claude mcp add --transport http aws-knowledge https://knowledge-mcp.global.api.aws
The managed aws comes in the Agent Toolkit for AWS. Easiest is the plugin, two steps on the same agent: first you register the marketplace (the plugin source), then you install the plugin from it.
/plugin marketplace add aws/agent-toolkit-for-aws # register the source (once)
/plugin install aws-core@agent-toolkit-for-aws # install the plugin
Prefer to do it by hand? Add it through the proxy:
claude mcp add-json aws-mcp --scope user '{"command":"uvx","args":["mcp-proxy-for-aws==1.6.0","https://aws-mcp.us-east-1.api.aws/mcp","--metadata","AWS_REGION=sa-east-1"]}'
The endpoint is regional (today us-east-1 and eu-central-1); you connect to us-east-1 and operate on resources in whatever region you pass in AWS_REGION. Check the current one in the official docs, since this can change. The steering equivalent here is a CLAUDE.md at the project root, with the same rules.
The security part you can't ignore
"Everything fails, all the time."
Werner Vogels, Amazon CTO
If there's one part not to skip, it's this one. Werner's right, and with an AI driving your account it's worth taking that literally: assume the agent will mess up sooner or later, and design for it. Giving it access to read and operate your account is as serious as it sounds, so it's worth doing carefully.
First thing: IAM is still the boss. The managed server doesn't go over your permissions, it rides on top of them. Treat the agent like a new coworker. Or better: like that fresh intern who does everything to the letter, no questions asked, and who's so afraid of getting it wrong that they don't even stop to think. The type who, if you tell them to go find the spark stockroom to store some in a bottle, will actually go looking. Yeah, the agent is just like that too: give it too much access and it'll use it, even when it makes no sense. So, least-privilege, scoped only to what the task needs, nothing beyond that. AWS added standardized IAM context keys for these managed MCP servers, so you can write policy that knows "this call came through the MCP server" and restrict accordingly.
Second: there's no long-lived key anywhere. The proxy signs with your temporary AWS CLI credentials, which rotate on their own (every 15 minutes or so). So no secret sits around in your shell history, your repo, or your .env, which is exactly where we tend to leak them.
Third: everything is auditable. CloudTrail logs every call and CloudWatch gives you the metrics. After an incident you can answer "what did the agent actually do?" with a straight face. If you can't answer that today about your current setup, that alone is reason enough to switch.
And one that's still coming: VPC endpoint support, for teams that need to keep this traffic inside the network boundary. If that's a hard requirement for you, wait for it before going to production.
My rule of thumb? One dedicated IAM role per agent purpose. If an agent gets compromised or goes sideways, the blast radius stops at that role. Don't reuse your admin identity. And don't hand it * on * "just to unblock the demo", because the demo becomes prod faster than you'd think.
Setting up the AWS account side (the essentials)
On the account side it's less than it seems, because the managed AWS MCP Server doesn't create IAM actions of its own. There's no mcp:Invoke to allow: it signs every call with SigV4 using your credentials and forwards it to the service, which authorizes against your usual policies. If your identity can't call logs:GetLogEvents, neither can the agent. Your current permissions are the boundary.
The quick-start is this: begin with a read-only identity (a dedicated role or an SSO permission set) and use the new context keys, aws:ViaAWSMCPService and aws:CalledViaAWSMCP, to deny destructive actions when the call comes from the agent, even if your role could do them. That way the agent reads all it wants and the dangerous verbs are blocked just for it. Then let CloudTrail show what it actually used and tighten the policy around that.
A simple guardrail, just so you get the idea:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "BlockDestructiveActionsViaMCP",
"Effect": "Deny",
"Action": ["dynamodb:DeleteTable", "s3:DeleteBucket", "lambda:DeleteFunction"],
"Resource": "*",
"Condition": { "Bool": { "aws:ViaAWSMCPService": "true" } }
}]
}
This setup deserves a post of its own, done as code. Later in the series I'll publish an "IAM for AI agents on AWS, with CDK" covering the full step by step (CLI, console and CDK), cdk-nag, org-wide SCP and multi-account. I'll link it here once it's out.
Which one to use: the 10-second decision
Just need it to get AWS right (syntax, service, region)? Go with Knowledge: turn it on, no credential, move on. Need it to read or change something in your account? Go with the managed one, scoped with IAM.
And here's a detail that changes the math: the managed one already includes documentation search, with no credentials, and AWS treats it as the successor to Knowledge. So you don't need to run both. Knowledge is still great for when you just want to look something up, with no credentials and nothing to install.
When NOT to reach for this
Because there's no silver bullet, and someone has to say it.
Don't drop this on a production account with no guardrails. Start in a sandbox and get your IAM boundaries right before the agent can touch anything that bills or deletes. In the Frugal Architect, Werner makes the point that cost is an architecture requirement, not something to find out at the end of the month, and with an agent firing off calls that goes double.
Don't grant broad permissions "for now". There's no "for now", trust me. Scope it from the first connection.
And don't leave anything irreversible on autopilot. Deletes, scaling actions, money movement: keep a human in the loop. The agent proposes, you approve.
Mind your region and compliance
A few things that matter if you operate outside us-east-1 (for me, that's sa-east-1, São Paulo).
Before pointing the agent anywhere, confirm the services and the managed server are available in your region. And here's the nice part: that's literally a question the Knowledge MCP Server answers for you. Check it instead of assuming.
On data residency and privacy laws (LGPD here in Brazil, GDPR and friends elsewhere), if the agent is going to touch resources with personal data, scope IAM so it can't read what it shouldn't, and use the CloudTrail trail as evidence of who accessed what. Auditability here isn't just good engineering, it's a compliance argument.
And for small teams: that "free" CloudTrail trail is gold when you don't have a dedicated security team. You get a record of everything the agent did without building anything.
To wrap up
There are two AWS MCP servers for two pains: knowledge (stop hallucinating) and action (operate the account safely).
The Knowledge server has no credential and no risk. Turn it on today, seriously.
The managed one gets you off
.env: it uses your temporary AWS CLI credentials (IAM/SigV4) instead of a long-lived secret, with least-privilege and everything logged to CloudTrail.You don't need to run both: the managed one already does doc search and is the successor to Knowledge. Use Knowledge for docs with no credentials; the managed one for the full package (docs + account).
If you've been doing the .env hack, relax, everyone has. But the tools to stop are right here, they're managed, and they're auditable. There's no good excuse left to keep handing your account's keys to a robot that occasionally goes off the rails.
This post kicks off a series on MCP and agents on AWS. Next up I go deep on two tracks: setting up IAM as code (CDK) and OpenAI landing on Bedrock. Which one first? Tell me in the comments.
Liked it? Drop a like, tell me what you think in the comments, and share it with your crew to keep the community strong. Thanks a lot for reading this far. See you in the next one? =D
Want to go deeper
AWS's open source MCP servers (awslabs/mcp), home of the Knowledge MCP Server
Agent Toolkit for AWS, where the managed AWS MCP Server lives
Prefer Portuguese? Read the PT version here.
Originally published on willpeixoto.dev.