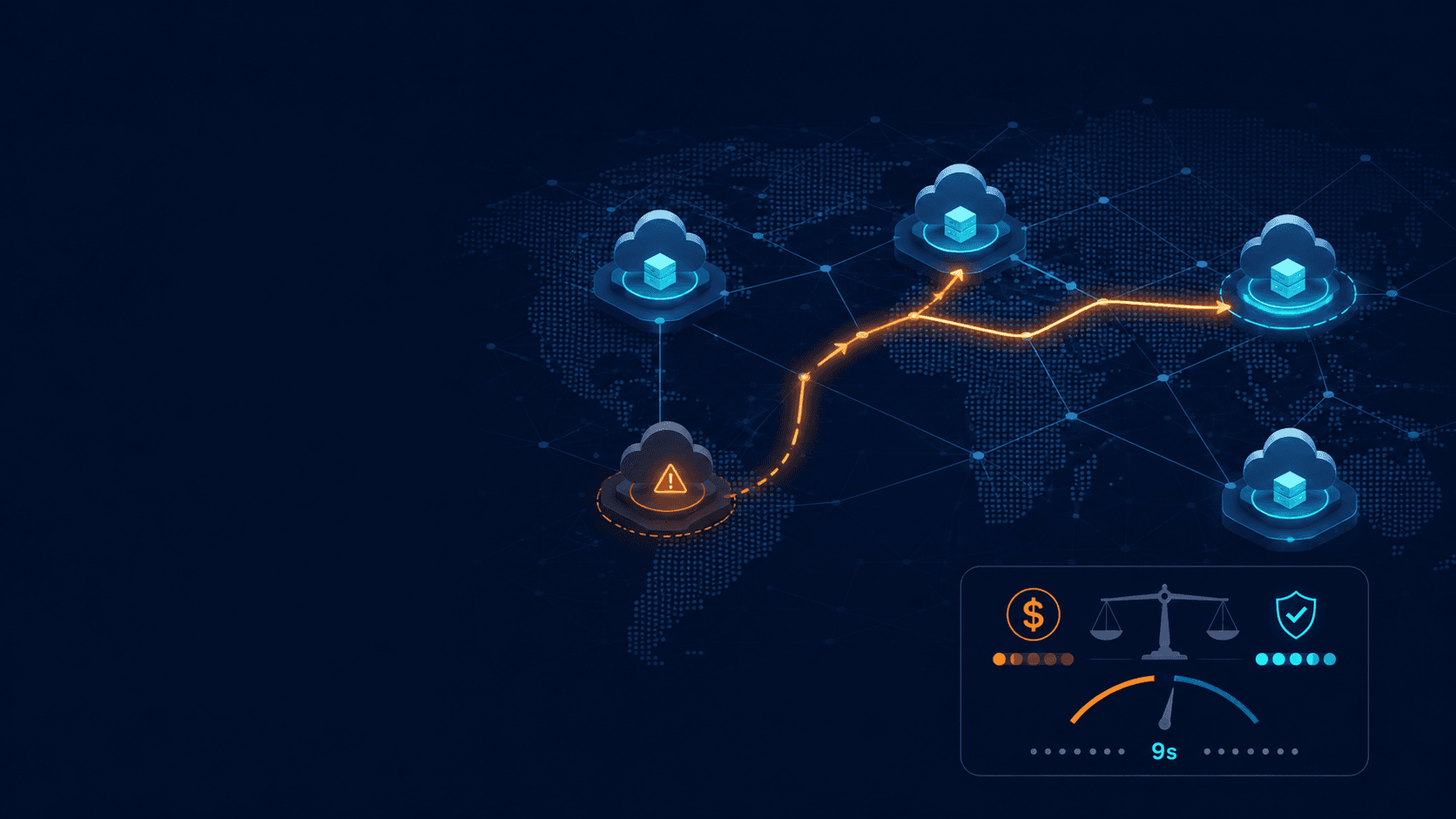
High Availability Has a Price: Resilience Is a Decision, Not a Stack
The cost of high availability: resilience starts with strategic decisions, not technology.
Staff Engineer @Serverless Guru | AWS Community Builder | Specialist in Serverless, AWS & Event-Driven Architectures | Speaker & Content Creator @willpeixoto.dev
🇧🇷 This article is also available in Portuguese: Resiliência em Arquitetura: A Decisão é Estratégica, não apenas Técnica
Resilience in Architecture: The Decision Is Strategic, Not Just Technical
The cost of high availability: resilience starts with strategic decisions, not technology.
After a major outage like the October 2025 event in AWS's us-east-1 region, the smoke clears and the same questions that haunt CTOs and architects always resurface:
"Should we be multi-region?" Or worse (and a little nostalgic): "Should we go back to on-premises?"
The truth is that the right answer is rarely technical.
It's strategic, first and foremost.
As Werner Vogels (Amazon CTO) likes to put it in his talks:
"Everything fails, all the time."
And that's exactly it. The central question isn't whether it will fail, it's when it will fail and how prepared you'll be when that inevitable moment arrives. Because it will arrive. Whether you're in the cloud, on-premises, or running a complex multi-cloud setup.
What really separates resilient teams isn't the absence of failure. It's the speed, clarity, and effectiveness with which they respond and recover.
And that's where real architectural maturity lives: resilience isn't about choosing "multi-region" or "on-premises." It's about understanding the inherent risk, documenting the choice transparently, and reacting with a plan.
1. The Context Behind the Question: The Paradox of Visible Failure
Every time there's a big outage, I notice technical teams and executives splitting into two extreme reactions, both driven by fear and pressure:
"We need to go multi-region, now! Cost is secondary!"
"See? The cloud isn't reliable. We should have stayed on-premises, where we had control!"
Both extremes are dangerous shortcuts.
Multi-region is not a vaccine against downtime, and going back to on-premises is not a synonym for control; it just moves the maintenance complexity onto you.
A Crucial Point of Reflection: The cloud doesn't fail more than a traditional data center, it just fails in a way that is more visible, shared, and, ironically, democratic. On AWS, problems scale globally and become trending topics in minutes. On-premises, they hide behind scattered logs, long repair times, and, often, they only hit you. Honestly: do you believe your company has a greater capacity than AWS (or any major cloud provider) to manage physical security, cabling, power, cooling, and, above all, the resilience of infrastructure at global scale?
Migrating or evolving an architecture, at its core, is not about "throwing everything away" or "buying the hype." It's about keeping what's good in the legacy and removing what limits growth.
This isn't a black-and-white fight of "Cloud vs. Data Center." It's a strategic game of Conscious Resilience vs. Comfort Zone.
2. Cost vs. Continuity: The Economics Behind the 9s
In the world of infrastructure, each additional "9" in your SLA (Service Level Agreement) doesn't just cost more. It costs exponentially more.
To illustrate the real impact of each availability tier, here's the maximum allowed downtime per year:
99% (two 9s): about 3.65 days of downtime per year. Cost and complexity: baseline (1x).
99.9% (three 9s): about 8 hours and 46 minutes of downtime per year. Cost and complexity: 1.5x to 2x the baseline.
99.99% (four 9s): about 52 minutes of downtime per year. Cost and complexity: 2x to 3x. Requires Multi-AZ and strong automation.
99.999% (five 9s): about 5 minutes of downtime per year. Cost and complexity: 3x and up. Requires flawless automation and, often, a Multi-Region architecture.
Each tier jump means more than doubling or tripling infrastructure; it also demands operational review and sophistication. And here's the catch: every additional 9 has to be justified by ROI (Return on Investment), never by technical pride.
📢 The Non-Negotiable Factor: Regulation. For sectors like finance, healthcare, or telecom, the SLA choice isn't always purely economic. Often, the availability requirement (and the data recovery capability, the RPO) is imposed by law or industry rules. In those cases, the debate isn't whether you can afford it, but how to hit the legally mandated SLA at the lowest possible cost and complexity, because the cost of a regulatory fine outweighs any technical saving.
Rule of Thumb for Complexity:
High availability (within a single region): can cost 1.5x to 2x the baseline.
Multi-Region (Active/Passive): can cost 2.5x to 3x.
Multi-Cloud (Active/Active): almost never reduces risk. On the contrary, it usually increases the failure surface and operational complexity.
3. Conscious Decisions: The Virtue of ADRs
Every architectural choice is a commitment based on a context, and that context is volatile. Without a record, the context is lost, which condemns us to redo decisions, revisit old discussions, and rack up unnecessary cost.
That's where the practice of ADRs (Architecture Decision Records) becomes crucial. These aren't 50-page documents. They're short records that capture the decision, the reason, and the accepted risk at a specific point in time.
Example ADR (focused on the accepted risk):
# ADR-014: Do not use multi-region replication in the MVP
Context:
- Current traffic < 10 req/s.
- Multi-region replication cost is estimated at > 3x current cost.
Decision:
Keep a single-region architecture (using Multi-AZ for intra-region HA),
with a daily cross-region backup.
Review Trigger:
After reaching an average of 100 req/s, or when the current SLA (99.95%)
starts causing business impact.
Accepted Risk / Consequence:
Risk of total service downtime if an outage affects the entire region
(estimated RTO of 4 hours for cross-region recovery).
An ADR doesn't prevent failure. But it prevents failure from catching the team by surprise, because the risk was mapped, accepted, and justified by the business. It's the map for future discussions.
4. Selective Resilience: Not Everything Needs HA (and That's Fine)
Selective resilience is a virtue of economy and clarity. Not every service needs global redundancy. Spending finite resources (money and engineering attention) on unnecessary redundancy is one of the biggest forms of waste in architecture.
Prioritize High Availability (HA) only for what truly matters:
Direct revenue functions: components critical to the financial transaction (e.g., checkout and payment APIs).
The critical customer journey: functions that block the core value of the product (e.g., login or the main catalog).
Regulatory and legal risk: services where failure triggers legal fines or breaches a penalizing contractual SLA.
Integrity of critical data: where data loss violates an acceptable RPO (e.g., mandatory data retention systems).
Everything else? It can be restored through a well-defined recovery playbook. Batch jobs, internal back-office systems, and dashboards can tolerate minutes (or even hours) of downtime, as long as the reprocessing plan is clear.
High availability with no purpose is like installing an airbag on a bicycle. It's a sophisticated solution to a problem that doesn't exist in that context.
5. Managed != Failure-Proof: The Serverless Mindset
A common mistake is believing that using serverless services (Lambda, DynamoDB, SQS, EventBridge) is a synonym for immunity to failure. It isn't.
Failure will come, and often from where you least expect it, because the serverless paradigm shifts the risk surface, it doesn't remove it.
The key point is this:
Managed services reduce your operational surface (you don't manage the OS, patching, or capacity), but they don't replace good design and preparation.
During the October 2025 us-east-1 outage, plenty of 100% serverless applications went down. Not because serverless failed them, but because they leaned on a single region. When DNS resolution for the regional DynamoDB endpoint broke, anything pinned to us-east-1 (directly, or indirectly through a global control plane like IAM or STS) broke with it. Multi-AZ wouldn't have saved you here: the endpoint was regional, not zonal. And the applications that recovered slowest were frequently the ones whose code answered the failure with aggressive, unbounded retries, turning one outage into a self-inflicted retry storm.
Real resilience doesn't come from AWS. It comes from the architecture you design on top of it.
6. The Decision Belongs to the Business, the Clarity to the Architect
The difference between "having an opinion" and "having influence" lies in your ability to translate technical complexity into strategic clarity. Your job isn't to scare the board with jargon. It's to give them the visibility they need to decide consciously.
Experience has taught me that a team's maturity can be measured precisely by its ability to ask the right question:
❓ Where Is Your Team's Maturity?
Immature teams focus on the tool:
They ask: "Which stack solves this?"
They ask: "Should we use K8s or Serverless?"
They ask: "What does Netflix do?"
Mature teams focus on risk and the business:
They ask: "What risk are we willing to accept for this cost?"
They ask: "What RTO/RPO does the end customer require from this service?"
They ask: "What does our business need to survive a disaster?"
The result is that two teams can use the exact same cloud: one scales predictably, the other lives in panic mode. The difference isn't the cloud. It's the level of understanding, documentation, and technical humility behind the decisions made.
The Common Trap: Who hasn't heard an executive say, "Technical decisions are up to the Architecture team"? What they're actually doing is transferring responsibility for defining business risk. Your team defines the HOW (the stack), but the Business defines the HOW MUCH (the acceptable RTO and RPO). It's your job to hand the question back, so the risk decision belongs to the business.
Translating Resilience Concepts for Leadership:
(After all, who hasn't heard: "Now translate that so I can understand it!")
1. Multi-Region Failover
Translation: Insurance against catastrophe. It guarantees that a
regional disaster won't take us offline for days,
reducing revenue loss to a few hours.
Question: How many hours (or minutes) of downtime can the
business accept for service X if an entire region goes down?
------------------------------------------------------------------
2. Active-Active Setup
Translation: Maximum, uninterrupted availability. It lets us perform
any maintenance or update without ever impacting the
end customer.
Question: Does service X need to be 100% continuous? Can we afford
a 15-minute maintenance window?
------------------------------------------------------------------
3. RTO / RPO
Translation: Defining the limit of the damage. These are the numbers
that tell us what we can lose, and for how long, before
fines or reputation become unsustainable.
Question: How much data (RPO) can we lose, and how long (RTO) does
the team have to restore the service before the business breaks?
------------------------------------------------------------------
4. SPOF (Single Point of Failure)
Translation: The Achilles' heel of revenue. It's the weak point that,
if broken, paralyzes the whole company. This is where the
risk must be zero.
Question: If this component goes down, what's the financial loss
in 1 hour?
7. Conclusion
There is no such thing as a failure-proof architecture.
But there is such a thing as an organization that is surprise-proof.
And it starts with conscious decisions, documentation (the ADRs), and the technical humility to accept that error and risk are part of the equation.
Teams that understand the "why" before diving into the "how" build systems that don't just scale. They survive, and grow predictably.
8. Essential References
For anyone who wants to go deeper on risk decisions and architectural patterns, these are the documents we use as a foundation for resilience on any cloud (with a focus on AWS):
AWS Well-Architected Framework (Reliability Pillar): the fundamental guide to understanding disaster recovery (DR) and high availability (HA) principles. Reliability Pillar
Disaster Recovery of Workloads on AWS: the key document for going deeper on RTO/RPO and choosing between patterns like Pilot Light and Active-Active. DR Whitepaper
DynamoDB Global Tables: an excellent practical case study of HA at the data layer, abstracting away multi-region complexity. DynamoDB Global Tables
EventBridge Resilience Guide: essential for anyone working with serverless, focused on event-based resilience patterns. EventBridge Resilience Guide
AWS Post-Event Summary: Amazon DynamoDB Service Disruption in US-EAST-1 (Oct 19-20, 2025): the primary source on the outage referenced in this article, straight from AWS. Service Disruption Summary
9. Essential Resilience Glossary
So everyone is on the same page, here are some key terms used in this article, explained simply:
High Availability (HA): the ability of a system to keep operating even when one or more of its components fail. Measured in "9s" (e.g., 99.99%).
Outage: an unplanned interruption of a service: the service goes down.
On-premises: infrastructure and data centers you own, physically located at the company (not in the cloud).
Multi-Region: using data centers in two or more different geographic cloud regions (e.g., US East and São Paulo) for maximum protection against regional disasters.
Multi-AZ (Multi-Availability Zone): using two or more Availability Zones (isolated, nearby data centers) within the same cloud region. This is the baseline HA pattern.
SLA (Service Level Agreement): a formal agreement defining the level of service a provider is expected to deliver (usually measured in uptime).
ROI (Return on Investment): a financial metric measuring the relationship between money earned (or saved) and money invested.
ADR (Architecture Decision Record): a short document recording an architectural decision, the reasoning, and the accepted risk at a specific point in time.
RTO (Recovery Time Objective): the maximum acceptable time a system can be down after a failure.
RPO (Recovery Point Objective): the amount of data (measured in time, e.g., 5 minutes) that can be lost during a disaster event.
Serverless: a cloud computing model where the provider manages all the infrastructure and the developer focuses only on the code, paying only for usage.
Circuit Breaker: a software pattern that, when a dependency starts failing repeatedly, "opens" the circuit to protect the rest of the application from cascading failures.
💡 Want to go deeper on resilience, orchestration, and the architect's strategic role in the serverless era?
I write about this kind of thing regularly. If this resonated, I'd like to hear it: how did your architecture hold up during the last regional outage, and, more importantly, which trade-offs had you already written down before it happened? Find me on LinkedIn and let's compare notes.